Reactive Agent Modelling
Abstract: In this work, we proposed a reactive agent model which can ensure safety without comprising the original purposes, by learning only high-level decisions from expert data and a low level decentralized controller guided by the jointly learned decentralized barrier certificates. Empirical results show that our learned road user simulation models can achieve a significant improvement in safety compared to state-of-the-art imitation learning and pure control-based methods, while being similar to human agents by having smaller error to the expert data. Moreover, our learned reactive agents are shown to generalize better to unseen traffic conditions, and react better to other road users and therefore can help understand challenging planning problems pragmatically.
Video demonstration
We study the problem of reactive and safe agent modeling for traffic simulators. Here “reactive” means the agents can react to the change of the surrounding environment (opposed to “dummy” agent models which can only follow existing trajectories), and “safe” refers to enforcing basic safety properties in traffic simulations (e.g. avoiding collisions, staying within lanes and below speed limits) via reasonable behaviors. An example is shown in Figure 1 where the pedestrians modeled by our reactive agent model can react to the incoming vehicle and avoid collisions with it. And in return, the vehicle can successfully plan a trajectory to pass through the crowd.
 |  |  |
Reactive and safe agent modeling is crucial for nowadays traffic simulator designs and developing modern self-driving techniques, because it give insights into how humans behave, how to learn from human reactions, how to team autonomous and human agents, and can also provide a more realistic simulation environment for autonomous car developers.
To make agents react like humans, researchers propose imitation learning (IL) methods to mimicking human (expert) behaviors from demonstrations, like behavioral cloning, inverse reinforcement learning (IRL) and generative adversarial imitation learning (GAIL). However, those methods do not directly enforce safety, which serves as a critical factor in traffic simulations. Model-free safe reinforcement learning (RL) methods can also be extended for multi-agent systems, but they draw less information from the expert trajectory and finding appropriate RL rewards is extremely challenging and tricky.
Focusing on learning safe behaviors, many learning methods are combined with barrier certificates and control barrier functions (CBF) to ensure safety. But they often use Sum-of-Squares to learn the certificate which is time-consuming, or handle all agents in the same type and run the same simple reach-avoid controller under simple environmental setup without real-world considerations. Instead, our learned model needs to handle real-world traffic scenarios and other users on the road, including other types of agents and non-reactive agents following some predefined trajectories. Moreover, our controllers are also designed in a hierarchical way to handle complex tasks. More details are shown below.
Problem formulation
We model the real-world traffic scenes as a heterogeneous multi-agent system, where different types of agents have different dynamic models, observations and criteria for safety. Our goal is to build such reactive agent models which can ensure safety of the system while behaving similarly to the real world traffic data.
Methodology
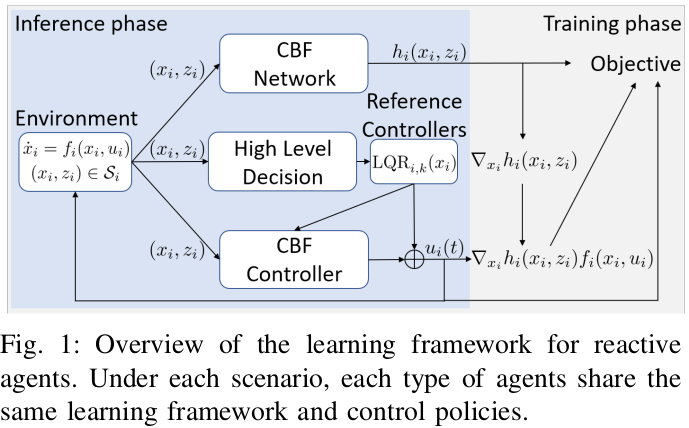
We propose a hierarchical and decentralized learnable framework to construct autonomous reactive agents with safety as the primary objective. As shown in Fig. 1, the learning framework for each type of agent contains a high-level decision/controller, a set of reference controllers, a CBF network and a CBF-guided controller. The high-level controller is pre-trained offline using expert trajectories to capture high-level decisions made by humans that are hard to define in CBF (e.g. when to switch lanes). Then during training in the simulation, the CBF network and CBF controller jointly learn to satisfy the CBF conditions. At the inference stage, the high-level controller selects a reference controller for different purposes (e.g. staying at the center of the lane, reaching destination, etc.), and the CBF controller rectifies the reference control command to ensure system’s safety while avoids diverging too much from the agents original purposes, hence being realistic.
Experimental results
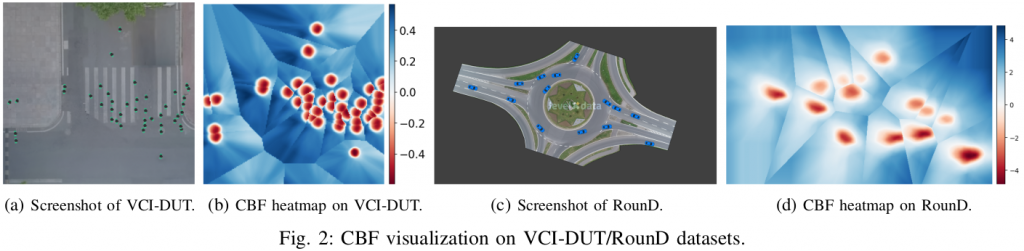
To illustrate what can be learned using the above framework, we first demonstrate contour plots of the learned CBF value on VCI-DUT and RounD datasets. The contour plots show the value of a new agent’s CBF for each location as if that agent were assigned to be in the scene. Under both scenarios, our CBF network outputs negative value when the location is close to other road participants (which is dangerous), and shows positive value at places far away from other agents (safe). Therefore our learned agents will prefer to go to locations that are “bluer”.
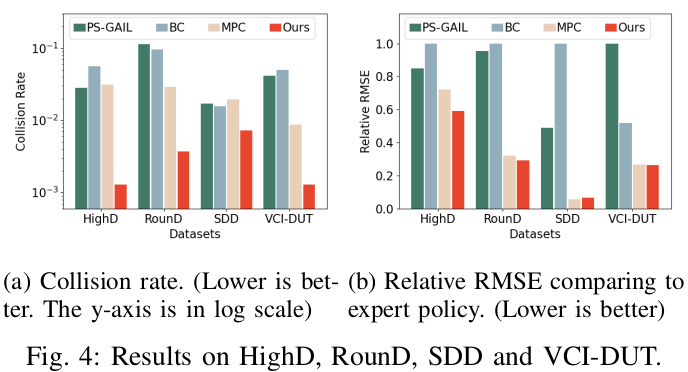
As shown in Fig. 4, on HighD, RounD, SDD and VCI-DUT datasets, our approach can achieve 53.8% ∼ 97.7% reduction in collision rates compared with BC (Behavior Cloning), PS-GAIL, and MPC (Model Predictive Control) approaches. For each simulation step, it takes 0.5 second for the MPC solver (therefore cannot really be used online), whereas our approach only needs 0.01 second, being 50X faster. Moreover, our approach can also achieve much lower RMSE (root mean square error ) even compared with the imitation learning method (PS-GAIL).
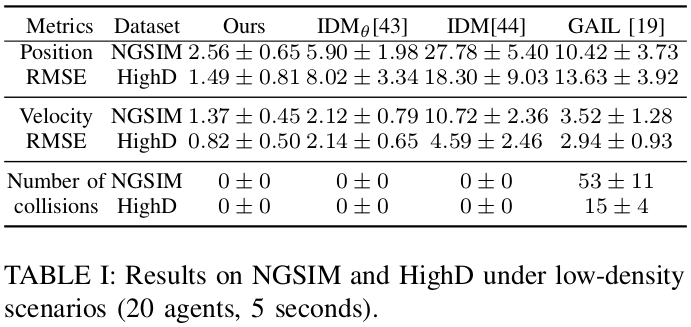
We then test our approach for NGSIM and HighD datasets under low density traffic. As shown in Table.I, without any calibration, our approach can achieve zero collision rates on both datasets and obtains the lowest RMSE in position and velocity, which shows the power of our learned CBF in terms of providing safety guarantees.
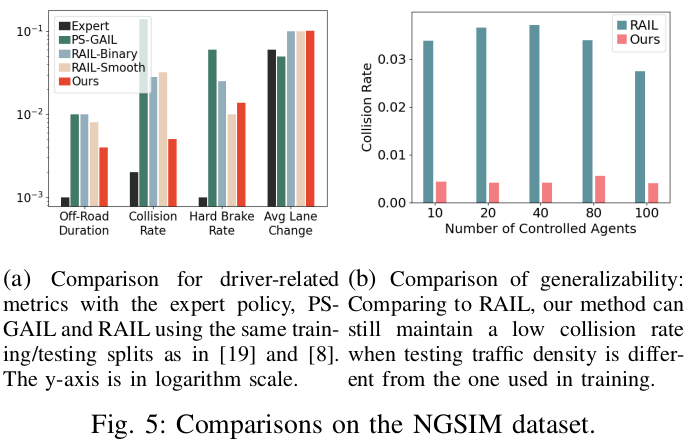
For challenging dense traffic cases in NGSIM, we further compare with PS-GAIL and RAIL as shown in Fig.5. With similar lane changing rates, our collision rate is almost 1/10 to the “RAIL-Smooth”. Our method also achieves a lower off-road duration. Compared to RAIL, our approach does result in a slightly higher hard brake rate, which might be due to the collision-avoidance intention in our CBF controller. Our RMSE is similar to RAIL and thus is not reported here. To show the generalizability of our approach, we train the model in NGSIM using only 20 agents then test on an increasing number of agents from 10 to 100. Our learned model can adapt to different traffic density and maintain a similar level of collision rates as shown in Fig.5 (b). As a comparison, RAIL is trained using 100 agents but behaves poorly when the density changes. When the density is low (N ≤ 40), the collision rate for RAIL goes even higher.
To demonstrate the use of reactive and safe agents we have learned, we design a challenging planning task for a vehicle to drive through a crowded street, where the scene is taken from VCI-DUT. As shown in Fig.6, when interacting with our learned reactive agents, the MPC-controlled car can successfully travel through the crowd safely, as our learned agents use a neural-CBF to produce safe reactions and therefore make a path for the car. Whereas in other cases the car is frozen and even goes backward as the pedestrians are not reacting to make a way for the car. This shows that safety-guided reactive agents can help solve some of the conservative issues in the developing self-driving algorithms.
