Learning Safe Multi-Agent Control with Decentralized Neural Barrier Certificates
Abstract: We study the multi-agent safe control problem where agents should avoid collisions to static obstacles and collisions with each other while reaching their goals. Our core idea is to learn the multi-agent control policy jointly with learning the control barrier functions as safety certificates. We propose a novel joint-learning framework that can be implemented in a decentralized fashion, which can adapt to an arbitrarily large number of agents. Our approach also shows exceptional generalization capability in that the control policy can be trained with 8 agents in one scenario, while being used on other scenarios with up to 1024 agents in complex multi-agent environments.
 | 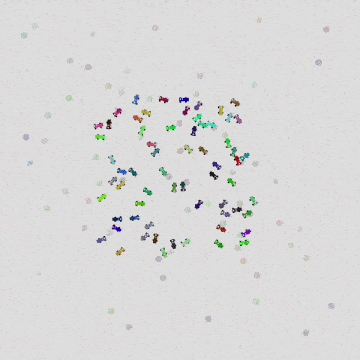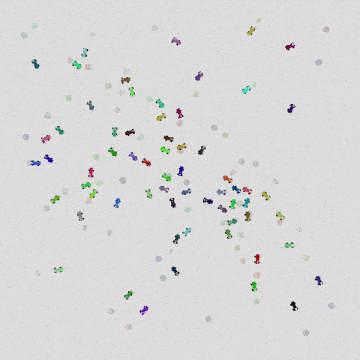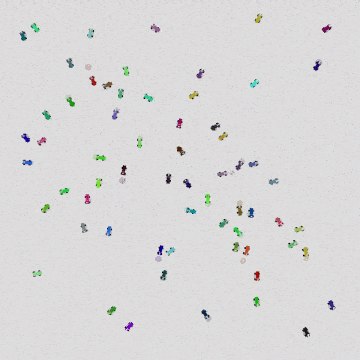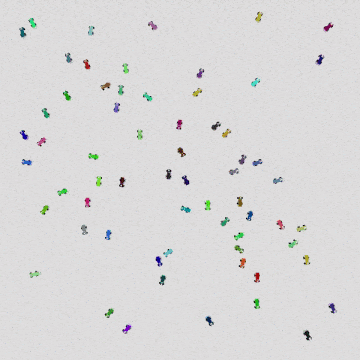 | 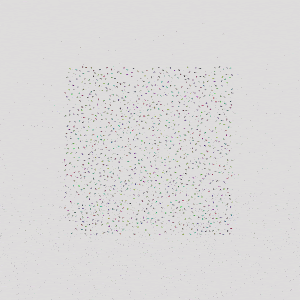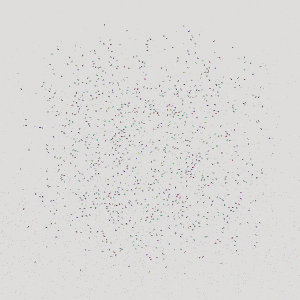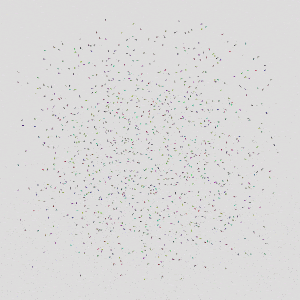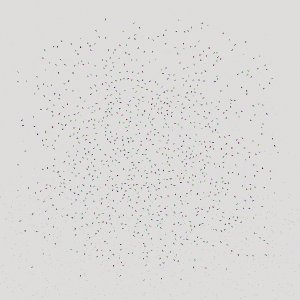 |
| 16 Cars | 64 Cars | 1024 Cars |
 |  |  |
| 32 Quadrotors | 256 Quadrotors | 1024 Quadrotors |
Method
Joint Learning of Controllers and Safety Certificates
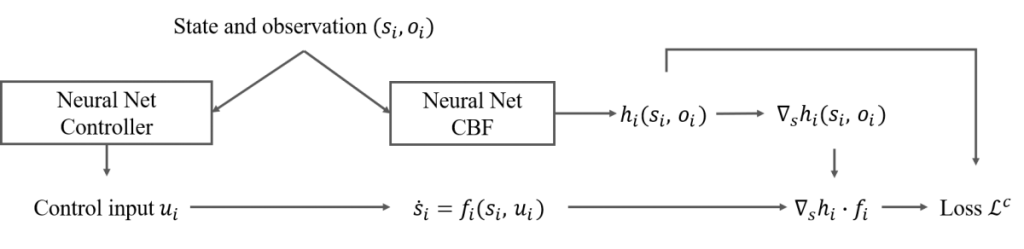
To guarantee safety of the learned controller, we propose to jointly learn a safety certificate with the controller. Control Barrier Functions (CBFs) give us a way of providing safety guarantees to the controller. If there exists a controller and a CBF that jointly satisfy the CBF conditions (see Section 3.1 in our paper), the controller is guaranteed to be safe. Maunally designing CBFs for complex dynamics is extremely difficult, so we designed a joint-learning framework that finds both the controller and the CBF.
Decentralized Controllers and CBFs
To scale up to an arbitrarily large number of agents, the controllers and CBFs are decentralized. In decentralized control, each agent has its own controller, and the same type of agents share the same controller parameters. By contrast, in centralized control, all agents are controlled by a central controller. The centralized controller cannot handle an arbitrarily large input and output space. Thus it is less scalable than decentralized controllers.
Quantity-permutation Invariant Observation Encoder
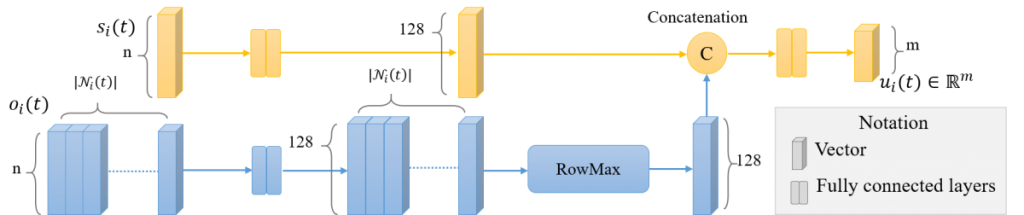
An agent only observes its neighbouring agents within a given distance. The quantity and permutation of the observation space is time-varying, and cannot be handled by fully connected neural networks. We proposed a quantity-permutation invariant observation encoder that converts the observation into a fixed-length vector.
Online Policy Refinement
We use the learned CBF to monitor the control actions generated by the policy. If the action violates the CBF condition, we leverage the CBF to refine the action by gradient descent to ensure the CBF conditions are satisfied.
Experiments
2D Ground Robots

We consider the 3 tasks for ground robots. The robots are required to reach their goals or follow the reference trajectories, while respecting the safety rules. We measure the safety rate and reward of each method.
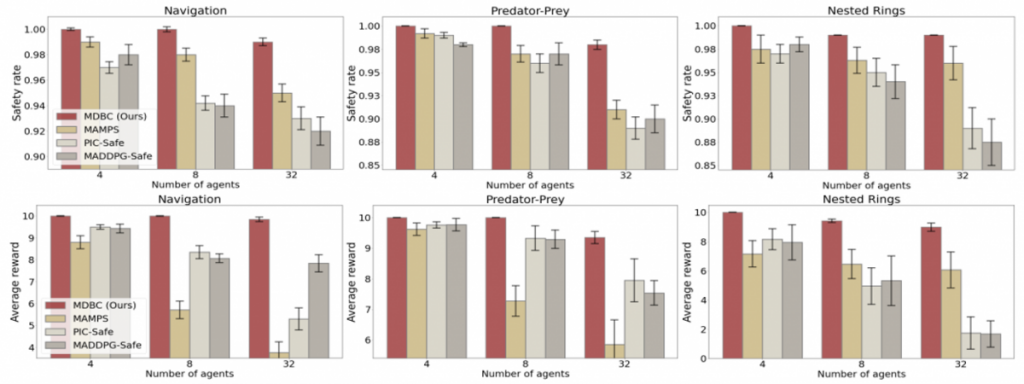
The first row: safety rate. The second row: reward. Our method shows remarkable performance compared with state-of-the-art multi-agent RL and planning methods.
3D Drones
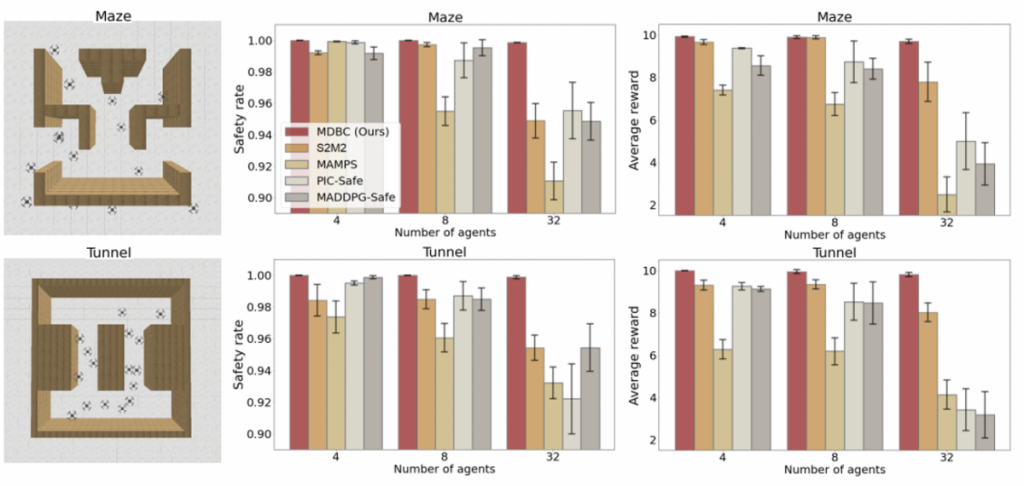
Our safety rate and reward consistently outperform state-of-the-art methods.
Generalization Capability
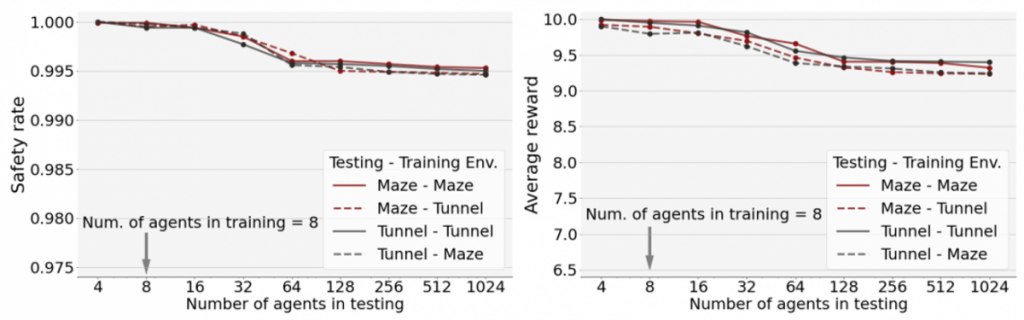
The controller trained with 8 agents can generalize to testing scenarios with more than 1000 agents, while keeping a high safety rate and average reward.
Resources
Code: https://github.com/Zengyi-Qin/macbf