Large-scale Multi-agent Safe Control with Neural Contraction Metrics and Barrier Certificates
Abstract: We study the multi-agent reach-avoid control problem for large-scale systems where each agent should avoid collisions with other agents and obstacles while reaching the goals. The key of our method to scale to a large number of agents is to design a decentralized multi-agent control framework and use data-driven approaches to jointly learn the controllers and their certificates for safety and goal-reaching. Our framework consists of three major components. First, a single-agent planner is employed for each agent to give a reference trajectory connecting to its next destination. Then, for each agent, a learned tracking controller is used to track the planned reference trajectory with exponential convergence rate even under disturbance, which is certified by a jointly learned control contraction metric. Finally, a learned decentralized control barrier function is used to adjust the tracking controller to make sure that each agent will not collide with other agents and obstacles while reaching the destination. Simulation results show that our method can maintain remarkable safety performance significantly outperform other leading multi-agent control approaches, including both learning-based and non-learning-based methods.

Introduction
Control certificates can serve as proofs for the satisfaction of the desired properties of a system, under certain control policies. For example, Control Contraction Metrics (CCM) ensure the existence of feedback controllers so that the controlled systems can be proved to converge to desired behaviors, and Control Barrier Functions (CBF) can supervise the synthesis of controllers such that the closed-loop (multi-agent) systems are guaranteed to always stay in certain invariant sets that encode safety requirements. We will exploit the combinatorial use of such control certificates to guide the synthesis of safe and robust controllers and provide strong theoretical guarantees.
The biggest challenge in using the above control theoretical approaches is the construction of certificates. It is extremely difficult to craft CCM and CBF by hand for complex nonlinear and nonholonomic systems. Other optimization-based approaches such as sum-of-squares (SoS) cannot scale to large-dimension and large-scale systems. Therefore, there are very few existing methods that scale to systems with hundreds or thousands of agents. Recent advancements in neural networks (NN) stem a growing interest in learning-based control certificates. However, all of these studies only concern single-agent systems. How to develop learning-based approaches for multi-agent safe control that are both provably dependable and scalable remains open.
In this paper, we present an exciting result in building a learning-based control framework for multi-agent systems that overcome the above hurdles. Our framework can produce safe and robust controllers for multi-agent dynamical systems to perform reach-avoid tasks and can scale to a very large number of agents.
Overview of the Proposed Framework
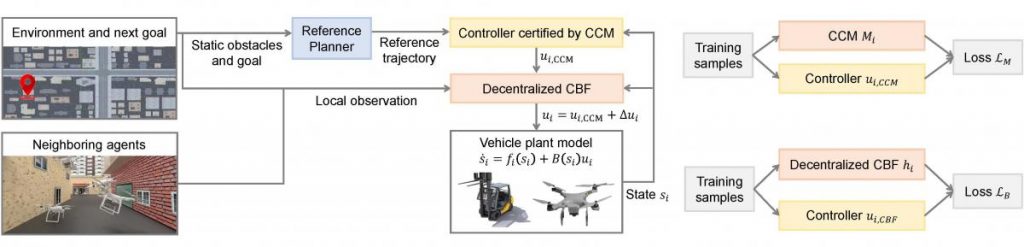
Our framework consists of three major components: a single-agent planner, a tracking controller certified by a learned CCM, and a learned decentralized CBF. First, the single-agent planner plans for each agent a reference trajectory connecting it to its next destination. Then, the controllers learned with CCM can guarantee that each agent can track the planned reference to reach its destination under disturbances, and the control input is further refined by the learned decentralized CBF to make sure that the agents will not collide with each other and other obstacles. We prove that such a certified controller can guarantee safety and goal-reaching for multi-agent reach-avoid tasks.
More importantly, we propose a novel learning framework that jointly learns multi-agent control policies and control certificates (i.e., CCM and CBF) from data, which can be implemented in a decentralized fashion and hence scalable to an arbitrary number of agents. We present the loss functions for the joint-learning framework, as well as the neural network architecture that enables the agents to handle complex multi-agent environments when the local topology constantly changes. The decentralized CBF can be seen as a contract among agents and allows agents to learn a mutual agreement with each other on how to avoid collisions. Once such a controller is achieved through the joint-learning framework, it can be applied to an arbitrary number of agents in scenarios that are different from the training scenarios, which resolves the fundamental scalability issue in multi-agent control. We also present several techniques that make the learning framework more effective and scalable for practical nonlinear and nonholonomic multi-agent systems.
Experimental Results
Evaluation criteria. Since the primal focus of this paper is the safety of multi-agent systems, we use collision reduction as a criteria to measure how many collision can be avoided compared to the baseline that directly follows the reference trajectory without collision avoidance. The method is safer when its collision reduction is higher. A 1.0 collision reduction means all collision can be avoided. In addition to the collision reduction, we also calculate the average reward that evaluates how good the task is accomplished in terms of goal reaching and safety. In order to evaluate the efficiency of different control methods, we measure the average time for all agents to reach the goals and define the relative time consumption metric.
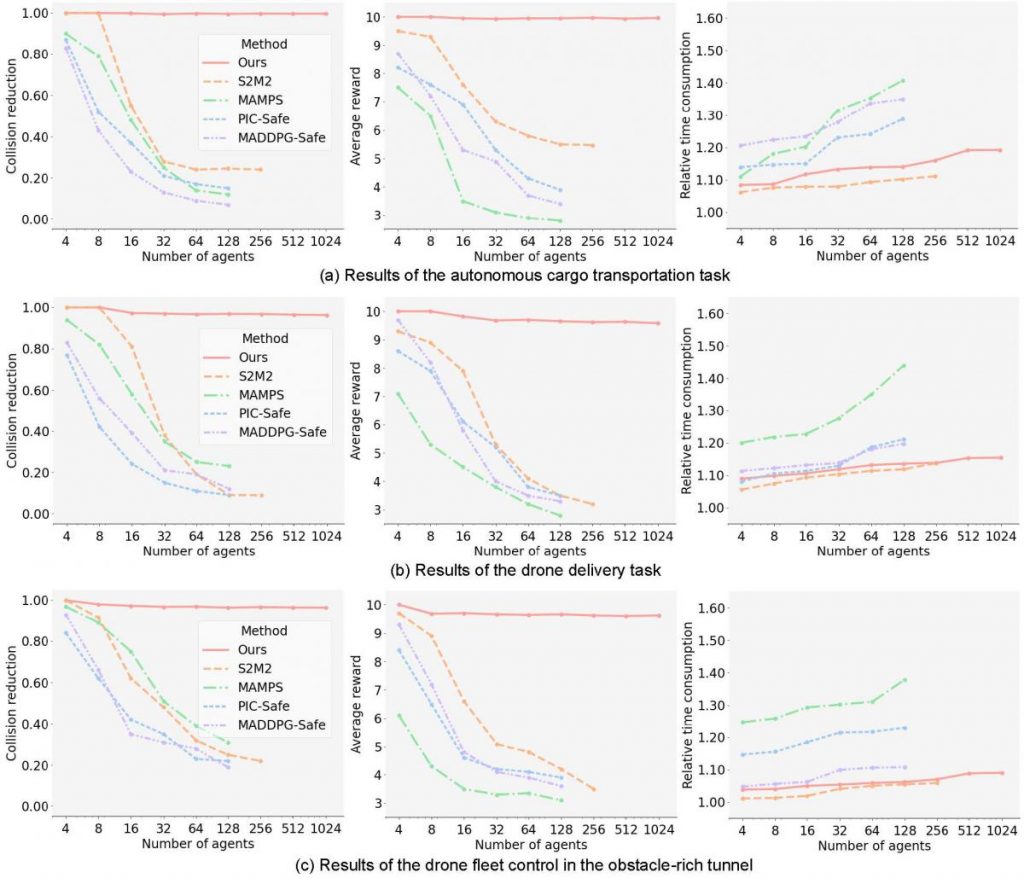
It is shown that our method is able to handle a very large number of agents and maintain a 0.96-1.0 collision reduction compared to the baseline, which means more than 96% collision among agents can be avoided. As the number of agents increases exponentially, there is only a slight performance drop for our method, while the compared methods exhibit drastic performance decline. Take the cargo transportation task as an example. When the number of agents grows from 4 to 256, the collision reduction of S2M2 decreases from 1.0 to 0.22, while using our method the number only decreases from 1.0 to 0.997. Similarly, in the drone delivery task with 128 agents, the collision reduction is 0.97 for our method and 0.12 for MADDPG-Safe, which demonstrates that our method can bring notable improvement in safety, even with a large number of agents. While being safe, our method is not conservative and does not sacrifice much in terms of time efficiency. Based on the relative time consumption, our goal-reaching time only increases 3%-17% compared to the baseline, depending on the number of agents and the type of task. In comparison, MAMPS is more conservative and requires 10%-43% more time than the baseline, because it tries to stop the agents if they are predicted to collide.
The results also demonstrate the generalization capability of our method to unseen scenarios. As we mentioned in our paper, the tracking controller and CCM are trained with uniform random samples drawn from the state and input space without seeing the testing environment. Also, the decentralized CBF is trained with 8 agents but tested in different environments with much more agents. Our method is able to generalize to these unseen scenarios with notable performance. Although we tested with at most 1024 agents in our experiments, 1024 is not the limit of our approach. Given sufficient computational resource, more agents can be handled because the proposed control framework is decentralized and the computation for each agent is parallel. Adding more agents will not delay the computation of the control input.

A visualization of the learned CBF is provided with 1 container and 5 agents. The heatmap is obtained by assigning a new agent to the scene and recording the output value of its CBF at each location. The velocities of all the agents are set to 0. It is shown that the CBF is negative in the vicinity of existing agents and obstacles, which means these locations are dangerous and can cause collision. At safe locations, the CBF is non-negative.
Implementation
The source code is available at https://github.com/Zengyi-Qin/LMSC