ICRA 2024 Paper Announcements
We are excited to announce that REALM will be presenting seven papers at ICRA 2024! Below you can find a brief description and dedicated project website for each paper.
AutoTAMP: Autoregressive Task and Motion Planning with LLMs as Translators and Checkers
Yongchao Chen1, Jacob Arkin2, Charles Dawson, Yang Zhang3, Nicholas Roy2, and Chuchu Fan.
Non-REALM Affiliation: 1. Harvard 2. MIT, CSAIL, RRG 3. IBM
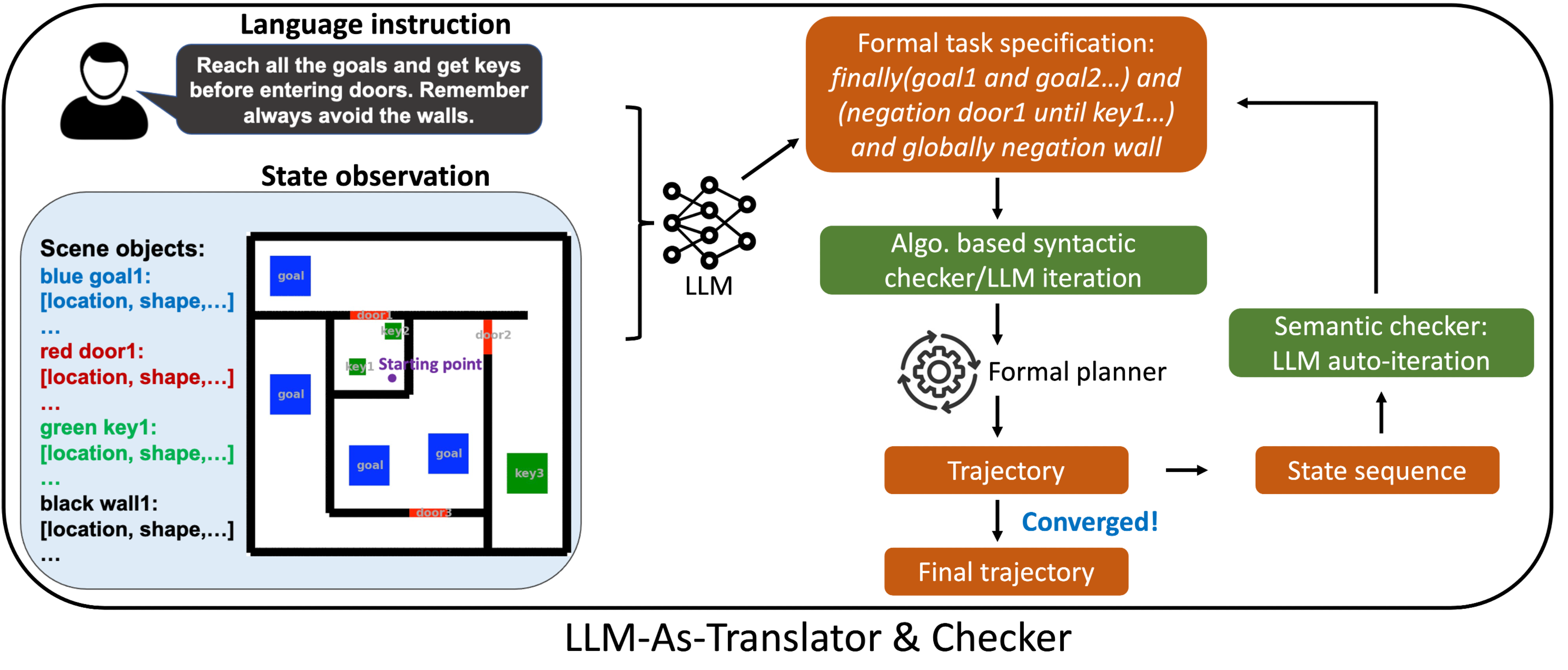
Brief Description: We want novice users to have an intuitive way to command robots, and large language models have recently emerged as a promising interface between natural language instructions and well-studied classic robot planners. While LLMs can translate from natural language to a formal representation for planners, they can make errors in which the meaning of the instruction is not well captured by the translation. To help address such semantic misalignments, we propose to first find a task and motion plan for the translation and use the plan as feedback for the LLM to evaluate whether it aligns with the original natural language instruction. We compared our method against several other LLM-based approaches on challenging tasks and found that our approach generally performed best; through ablations, we further found that the planner feedback significantly reduced errors of translation semantic misalignment.
Project Website: https://yongchao98.github.io/MIT-REALM-AutoTAMP/
Scalable Multi-Robot Collaboration with Large Language Models: Centralized or Decentralized Systems?
Yongchao Chen1, Jacob Arkin2, Yang Zhang3, Nicholas Roy2, and Chuchu Fan.
Non-REALM Affiliation: 1. Harvard 2. MIT, CSAIL, RRG 3. IBM
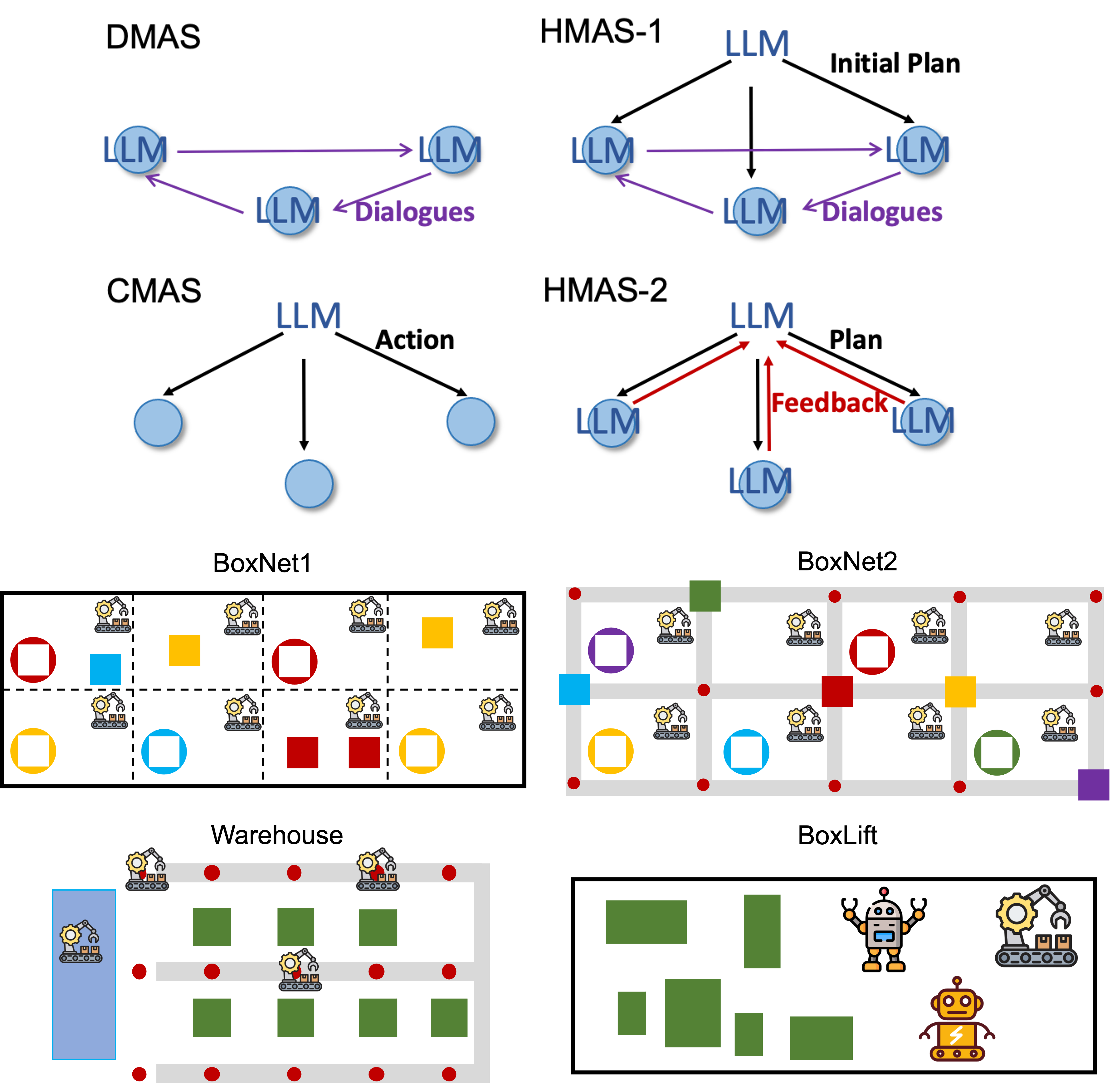
Brief Description: This work explores the use of pre-trained large language models (LLMs) for planning tasks involving multiple robots. While LLMs have shown effectiveness in single-robot tasks through advanced prompting techniques, multi-robot planning presents new challenges such as coordination and context window limitations. The study investigates the performance of four multi-agent communication frameworks (centralized, decentralized, and two hybrids) in various 2D coordination-dependent task scenarios with an increasing number of agents. The findings indicate that a hybrid communication framework offers superior task success rates and scales better with more agents. Additionally, the effectiveness of these hybrid frameworks is demonstrated in 3D simulations, taking into account vision-to-text conversion and dynamical errors.
Project Website: https://yongchao98.github.io/MIT-REALM-Multi-Robot/
Efficient Motion Planning for Manipulators with Control Barrier Function-Induced Neural Controller
Mingxin Yu, Chenning Yu1, M-Mahdi Naddaf-Sh2, Devesh Upadhyay2, Sicun Gao1, and Chuchu Fan
Non-REALM Affiliation: 1. University of California, San Diego 2. Ford Motor Company
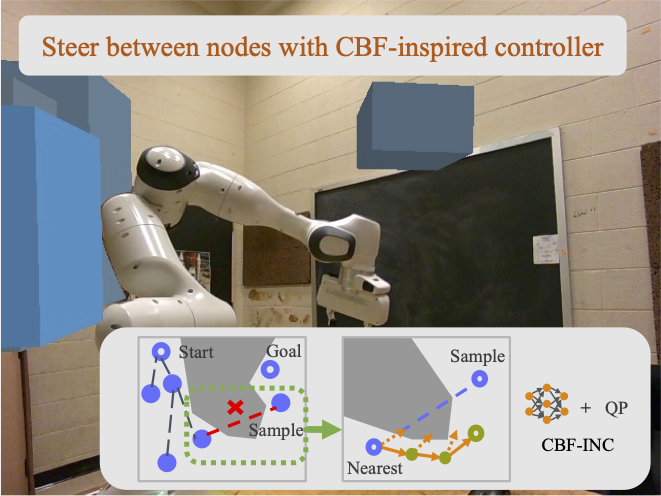
Brief Description: Planning safe execution path for manipulators in crowded environments often suffer from expensive collision checking and high sampling complexity, which make them difficult to use in real time. To address this issue, we propose a new generalizable control barrier function (CBF)-based steering controller to reduce the number of samples needed in a sampling-based motion planner RRT. Our method combines the strength of CBF for real-time collision-avoidance control and RRT for long-horizon motion planning, by using CBF-induced neural controller (CBF-INC) to generate control signals that steer the system towards sampled configurations by RRT. CBF-INC is learned as Neural Networks and has two variants handling different inputs, respectively: state (signed distance) input and point-cloud input from LiDAR. Compared to manually crafted CBF which suffers from over-approximating robot geometry, CBF-INC can balance safety and goal-reaching better without being over-conservative. We demonstrate that our method increase the success rate while reducing the number of explored nodes, compared with other steering controllers.
Project Website: https://mit-realm.github.io/CBF-INC-RRT-website/
ConBaT: Control Barrier Transformer for Safe Policy Learning
Yue Meng, Sai Vemprala1, Rogerio Bonatti1, Chuchu Fan and Ashish Kapoor1
Non-REALM Affiliation: 1. Microsoft Research
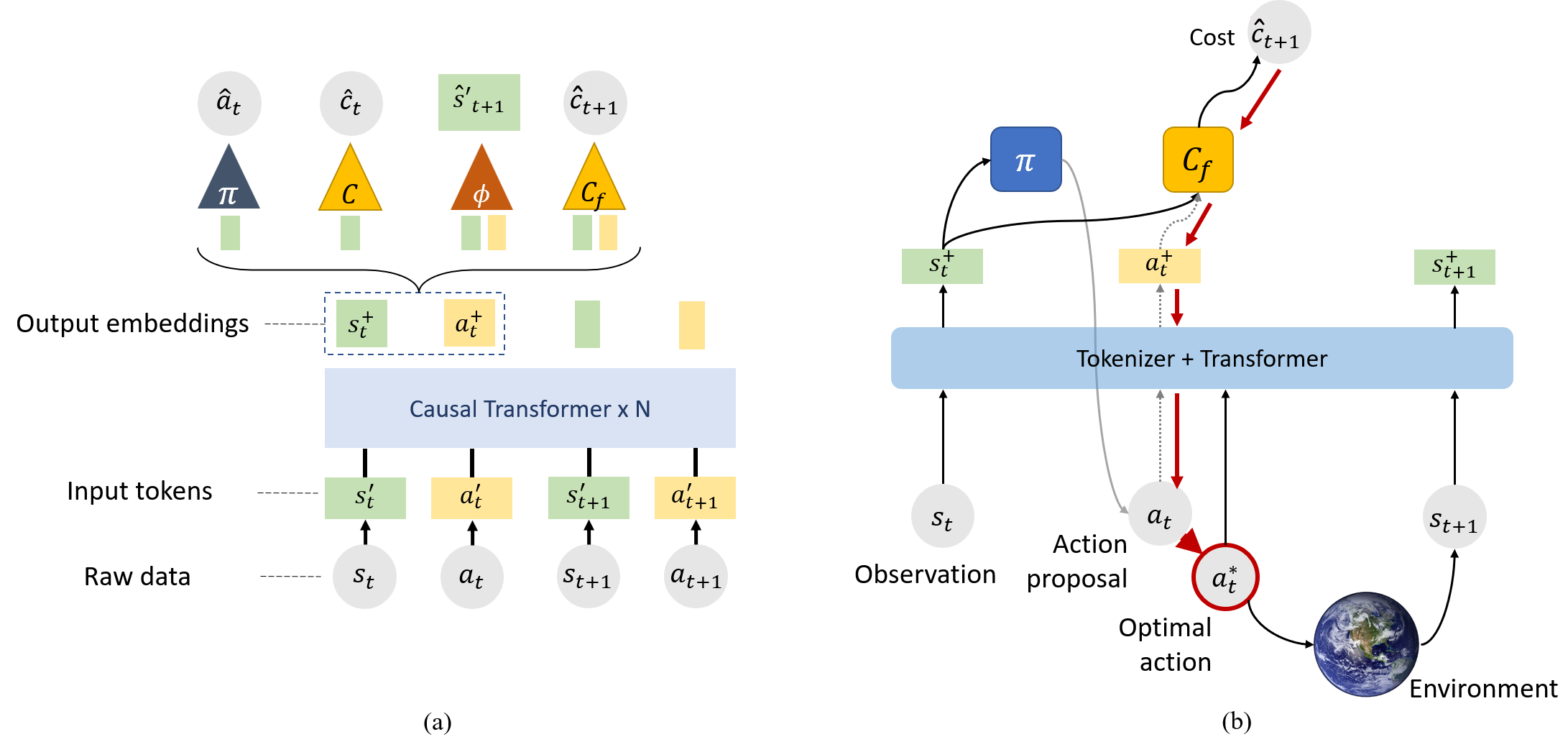
Brief Description: Large-scale self-supervised models have recently revolutionized our ability to perform a variety of tasks within the vision and language domains. However, using such models for autonomous systems is challenging because of safety requirements: besides executing correct actions, an autonomous agent must also avoid the high cost and potentially fatal critical mistakes. Traditionally, self-supervised training mainly focuses on imitating previously observed behaviors, and the training demonstrations carry no notion of which behaviors should be explicitly avoided. In this work, we propose Control Barrier Transformer (ConBaT), an approach that learns safe behaviors from demonstrations in a self-supervised fashion. ConBaT is inspired by the concept of control barrier functions in control theory and uses a causal transformer that learns to predict safe robot actions autoregressively using a critic that requires minimal safety data labeling. During deployment, we employ a lightweight online optimization to find actions that ensure future states lie within the learned safe set. We apply our approach to different simulated control tasks and show that our method results in safer control policies compared to other classical and learning-based methods such as imitation learning, reinforcement learning, and model predictive control.
Project Website: https://mit-realm.github.io/conbat/
How to Train Your Neural Control Barrier Function: Learning Safety Filters for Complex Input-Constrained Systems
Oswin So, Zachary Serlin1, Makai Mann1, Jake Gonzales1,
Kwesi Rutledge, Nicholas Roy, Chuchu Fan
Non-REALM Affiliation: 1. Lincoln Labs

Brief Description: Control barrier functions (CBF) have become popular as a safety filter to guarantee the safety of nonlinear dynamical systems for arbitrary inputs. However, it is difficult to construct functions that satisfy the CBF constraints for high relative degree systems with input constraints. To address these challenges, recent work has explored learning CBFs using neural networks via neural CBF (NCBF). However, such methods face difficulties when scaling to higher dimensional systems under input constraints. In this work, we first identify challenges that NCBFs face during training. Next, to address these challenges, we propose policy neural CBF (PNCBF), a method of constructing CBFs by learning the value function of a nominal policy, and show that the value function of the maximum-over-time cost is a CBF. We demonstrate the effectiveness of our method in simulation on a variety of systems ranging from toy linear systems to a jet aircraft with a 16-dimensional state space. Finally, we validate our approach on a two-agent quadcopter system on hardware under tight input constraints.
Project Website: https://mit-realm.github.io/pncbf/
Signal Temporal Logic Neural Predictive Control
Yue Meng, Chuchu Fan
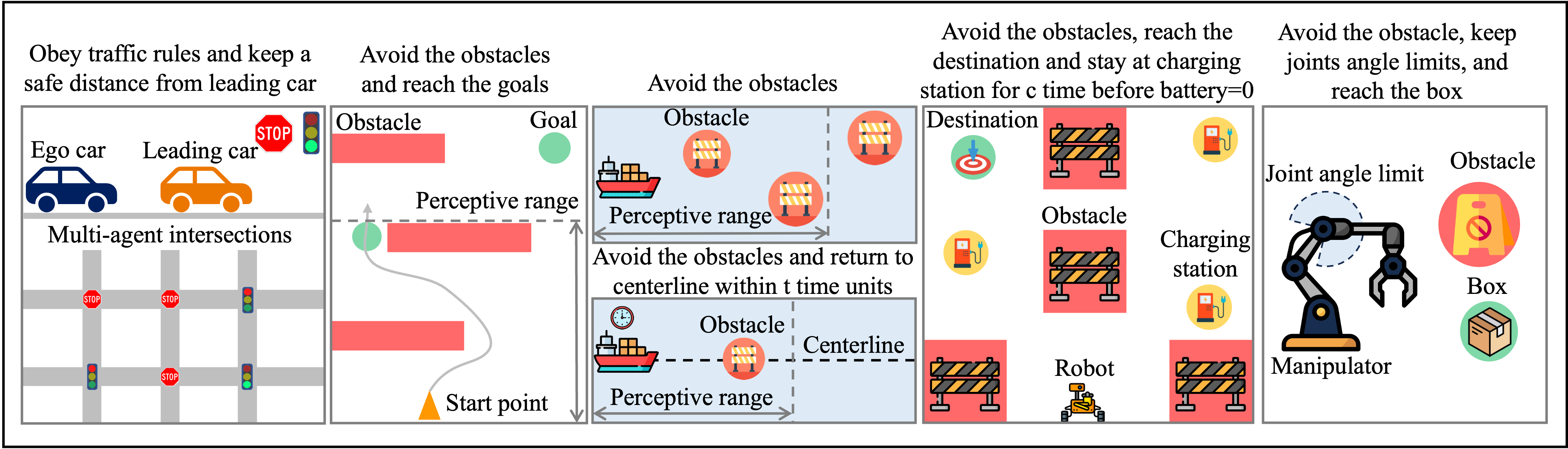
Brief Description: Ensuring safety and meeting temporal specifications are critical challenges for long-term robotic tasks. Signal temporal logic (STL) has been widely used to systematically and rigorously specify these requirements. However, traditional methods of finding the control policy under those STL requirements are computationally complex and not scalable to high-dimensional or systems with complex nonlinear dynamics. Reinforcement learning (RL) methods can learn the policy to satisfy the STL specifications via hand-crafted or STL-inspired rewards, but might encounter unexpected behaviors due to ambiguity and sparsity in the reward. In this letter, we propose a method to directly learn a neural network controller to satisfy the requirements specified in STL. Our controller learns to roll out trajectories to maximize the STL robustness score in training. In testing, similar to Model Predictive Control (MPC), the learned controller predicts a trajectory within a planning horizon to ensure the satisfaction of the STL requirement in deployment. A backup policy is designed to ensure safety when our controller fails. Our approach can adapt to various initial conditions and environmental parameters. We conduct experiments on six tasks, where our method with the backup policy outperforms the classical methods (MPC, STL-solver), model-free and model-based RL methods in STL satisfaction rate, especially on tasks with complex STL specifications while being 10X-100X faster than the classical methods.
Project Website: https://mit-realm.github.io/stl_mpc/
Shield Model Predictive Path Integral: A Computationally Efficient Robust MPC Method Using Control Barrier Functions
Ji Yin1, Charles Dawson, Chuchu Fan and Panagiotis Tsiotras1
Non-REALM Affiliation: 1. Georgia Institute of Technology
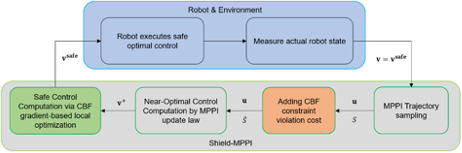
Brief Description: Model Predictive Path Integral (MPPI) control is a type of sampling-based model predictive control that simulates thousands of trajectories and uses these trajectories to synthesize optimal controls on-the-fly. In practice, however, MPPI encounters problems limiting its application. For instance, it has been observed that MPPI tends to make poor decisions if unmodeled dynamics or environmental disturbances exist, preventing its use in safety-critical applications. Moreover, the multi-threaded simulations used by MPPI require significant onboard computational resources, making the algorithm inaccessible to robots without modern GPUs. To alleviate these issues, we propose a novel (Shield-MPPI) algorithm that provides robustness against unpredicted disturbances and achieves real-time planning using a much smaller number of parallel simulations on regular CPUs. The novel Shield-MPPI algorithm is tested on an aggressive autonomous racing platform both in simulation and in hardware. The results show that the proposed controller greatly reduces the number of constraint violations compared to state-of-the-art robust MPPI variants and stochastic MPC methods.
Project Website: forthcoming