NeurIPS 2025 Paper Announcements
We are excited to announce that REALM will be presenting two papers at NeurIPS 2025! Below you can find a brief description and dedicated project website for each paper.
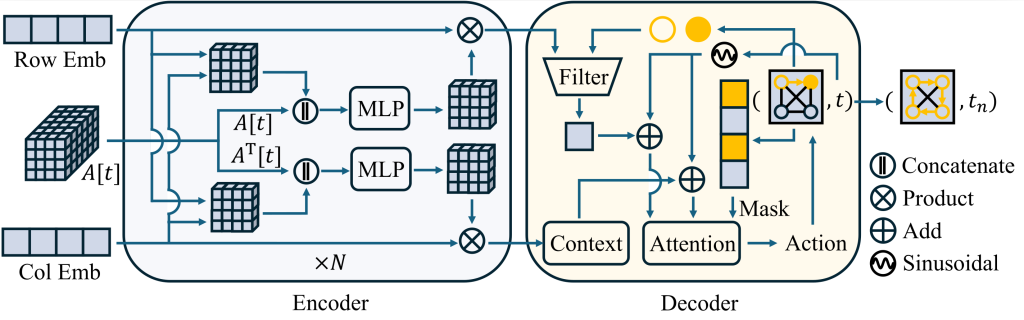
Neural Combinatorial Optimization for Time Dependent Traveling Salesman Problem
Ruixiao Yang and Chuchu Fan
MIT
- The paper addresses the Time-Dependent Traveling Salesman Problem (TDTSP), in which travel times between locations vary with departure time due to real-world factors such as traffic congestion.
- We propose a novel neural architecture that uses an adjacency tensor and a dual-graph attention encoder to capture complex spatiotemporal dynamics simultaneously. The solution also includes an inference-time Mixture of Experts (MoE) and local search refinement to handle instances in which temporal dependencies significantly alter the optimal route.
- The model achieves state-of-the-art performance, outperforming existing heuristics and neural baselines as problem sizes grow. Beyond performance, we find that many TDTSP instances in real-world data maintain static optimal solutions, prompting us to propose a more rigorous evaluation method focused on “selected instances” in which time-aware routing provides real benefits.
HMARL-CBF – Hierarchical Multi-Agent Reinforcement Learning with Control Barrier Functions for Safety-Critical Autonomous Systems
H M Sabbir Ahmad1,2, Ehsan Sabouni1, Alex Wasilkoff1, Param Budhraja1, Zijian Guo1, Songyuan Zhang2, Chuchu Fan2, Christos G. Cassandras1, Wenchao Li1
1BU 2MIT
- This paper addresses the problem of safe policy learning for safety-critical multi-agent autonomous systems.
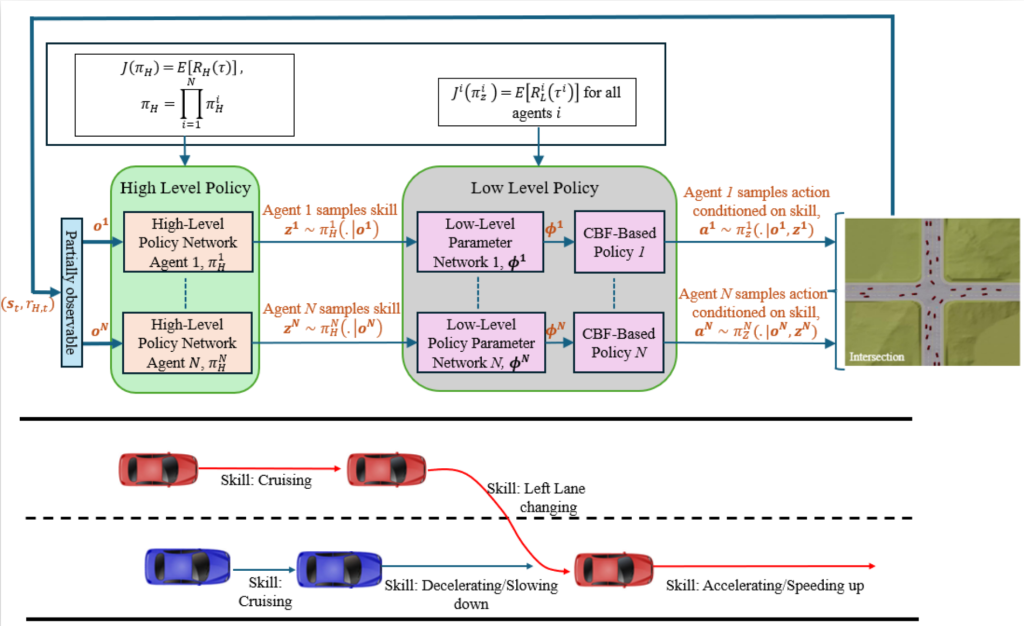
- We introduce a novel centralized-training–decentralized-execution (CTDE) hierarchical multi-agent reinforcement learning framework that guarantees safety using Control Barrier Functions (CBFs). This approach enforces pointwise-in-time safety constraints throughout both training and execution across each trajectory.
- Our hierarchical structure leverages skill-based decomposition, where the high-level policy coordinates cooperative behaviors across agents, while the low-level policy learns and executes safe skills guided by CBF-based safety constraints. This design guarantees safety both during training and in real-world deployment.
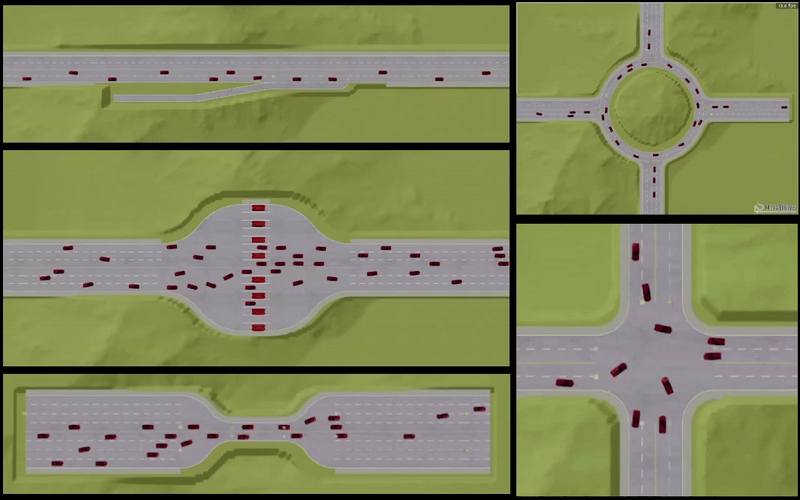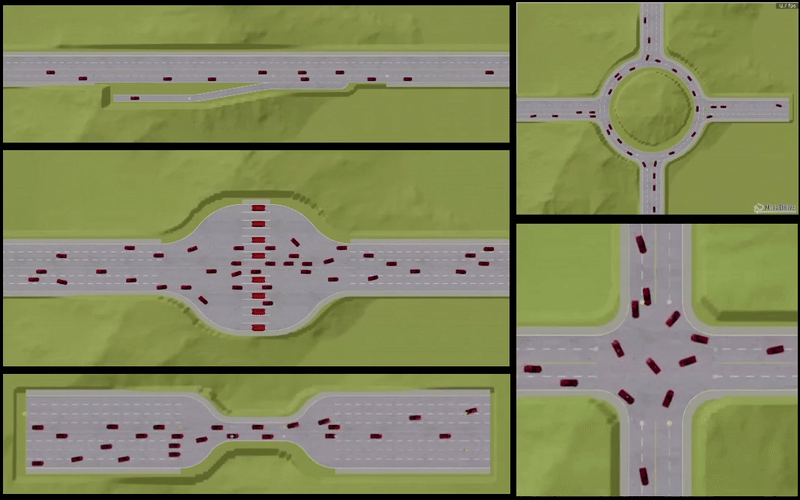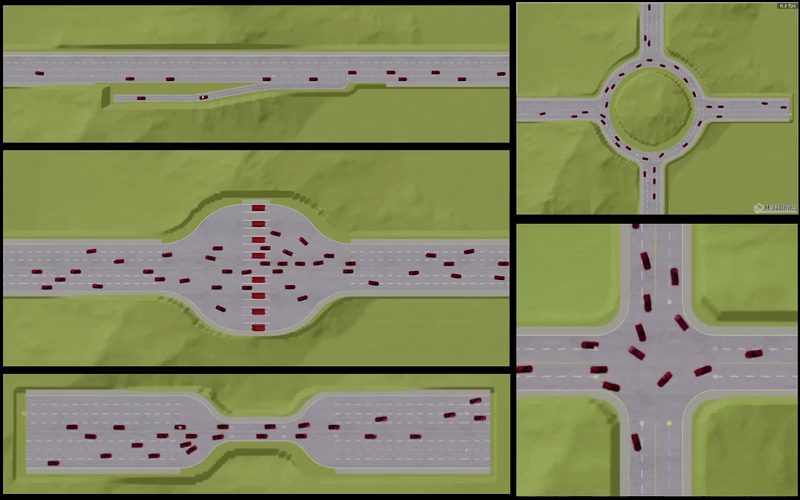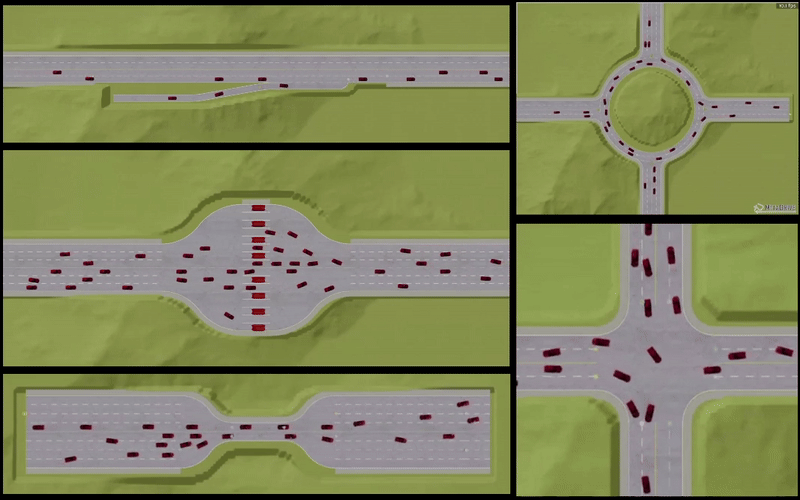
- We validate our proposed approach on challenging conflicting environment scenarios where a large number of agents must each travel safely from their origin to their destination without colliding with other agents. Simulation results demonstrate superior performance and safety compliance, achieving a near-perfect (>= 95%) success/safety rate compared to existing benchmark methods.