ICLR 2026 Paper Announcements
We are excited to announce that REALM will be presenting seven papers at ICLR 2026! Below you can find a brief description and dedicated project website for each paper.
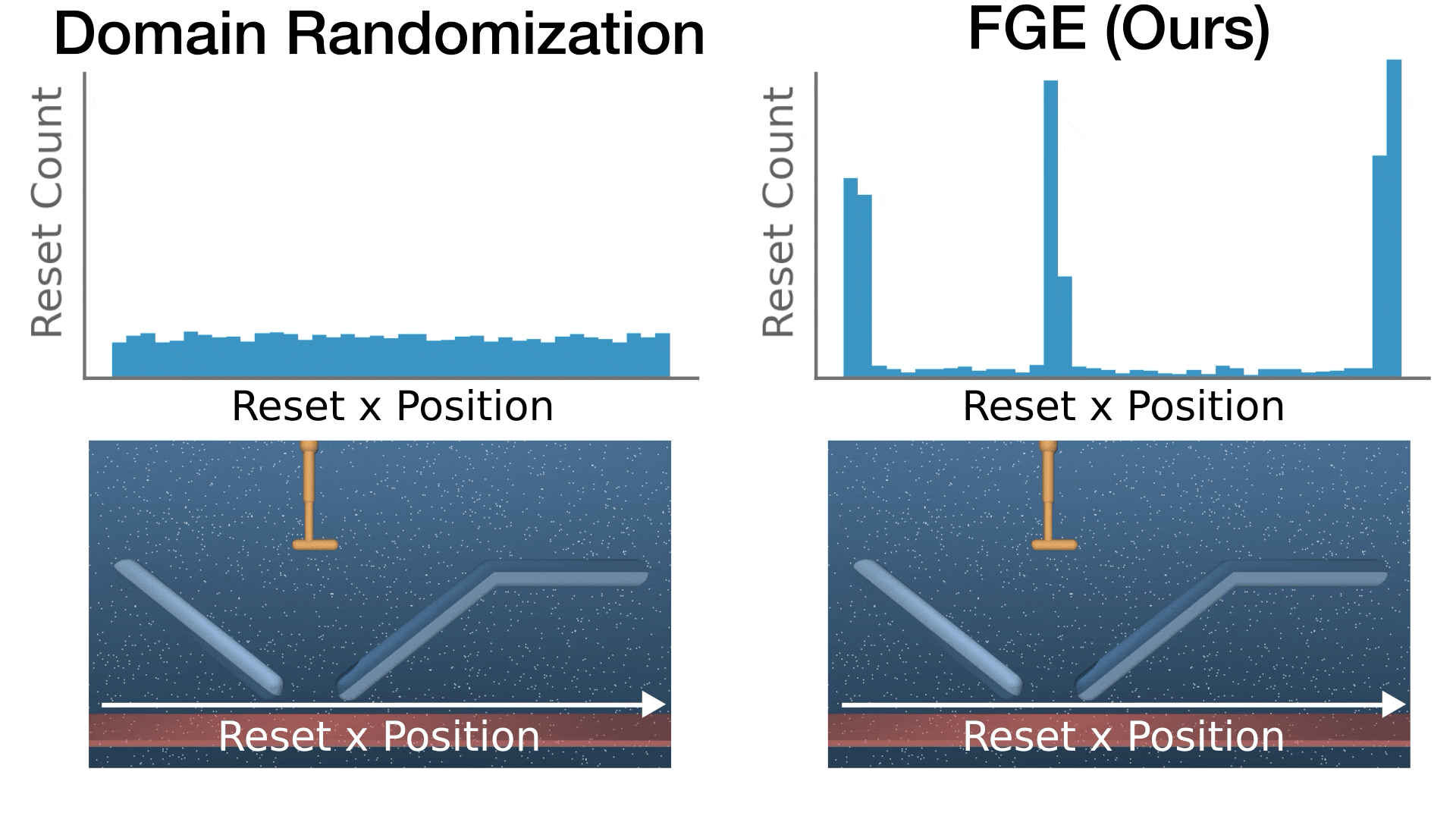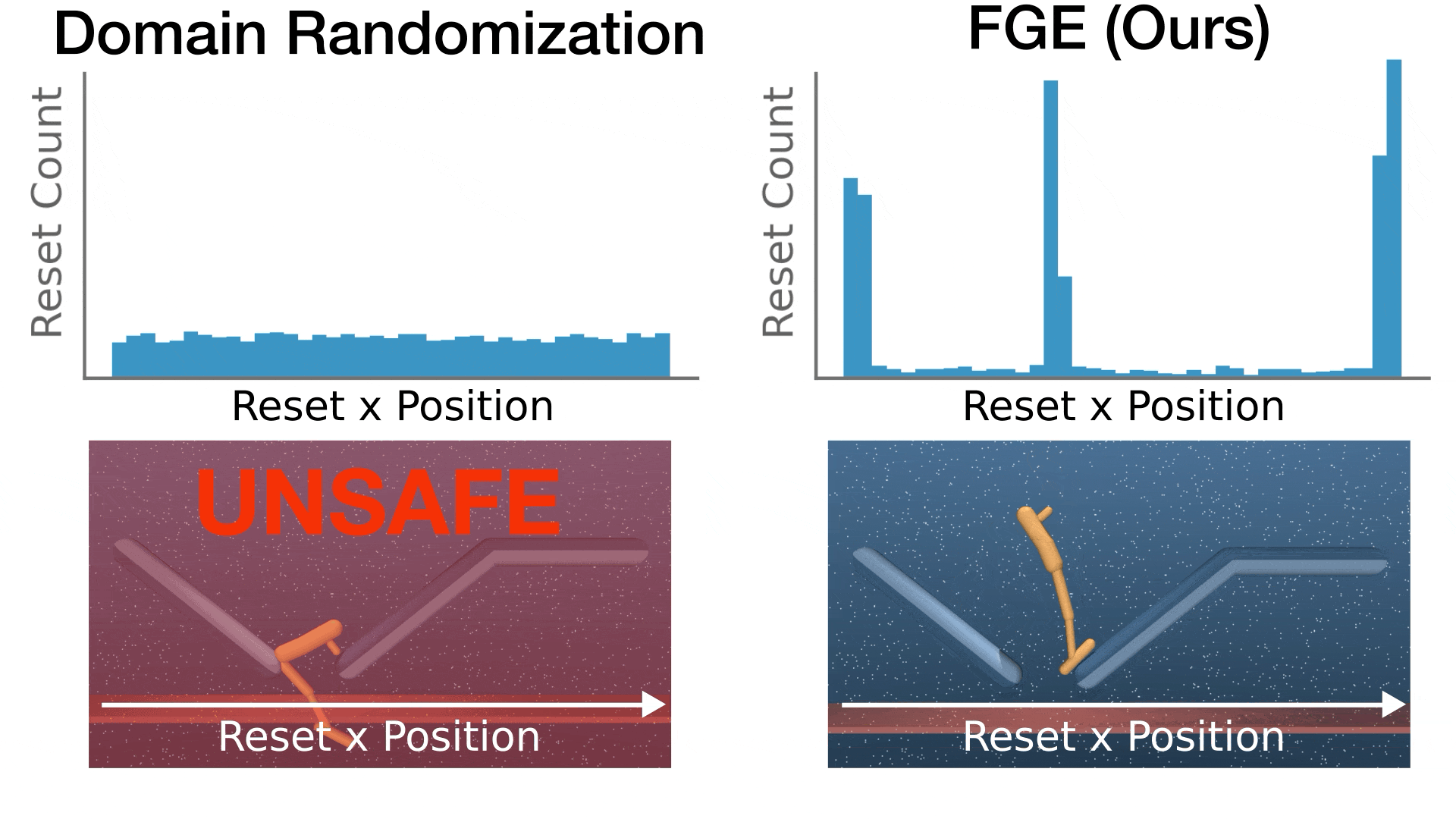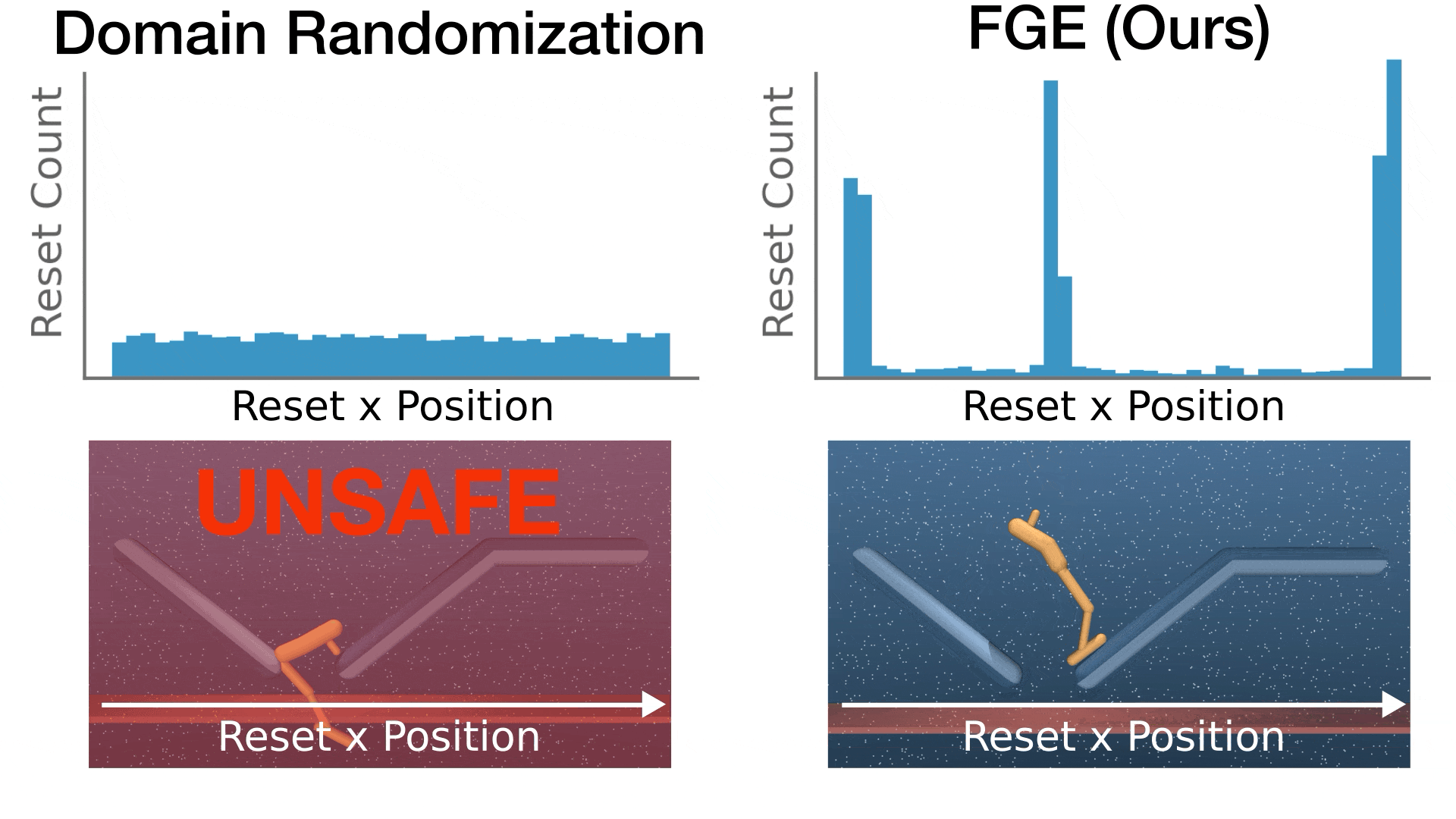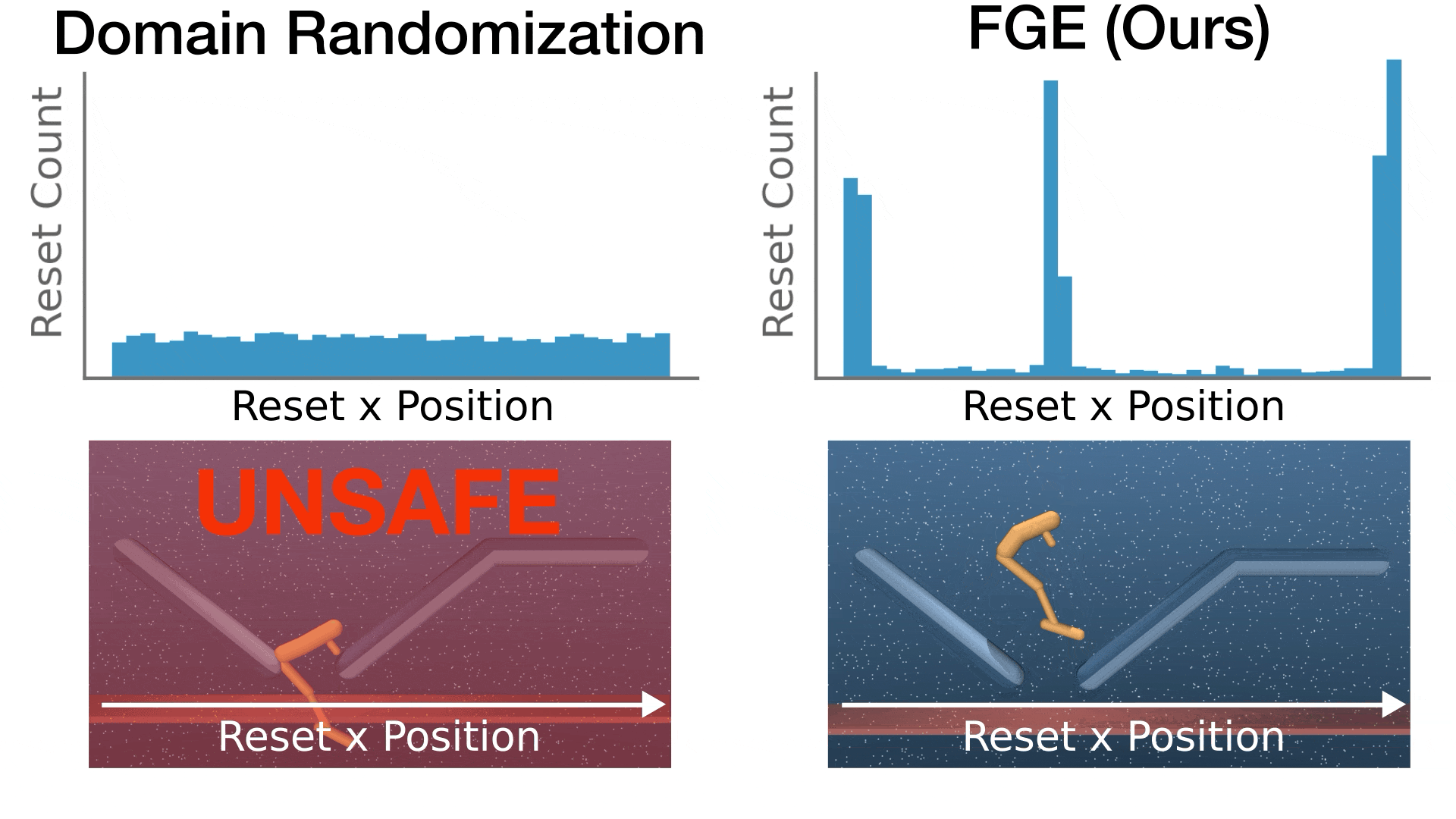
Solving Parameter-Robust Avoid Problems with Unknown Feasibility using Reinforcement Learning
Oswin So1, Eric Yu1, Songyuan Zhang1, Matthew Cleaveland2, Mitchell Black2, Chuchu Fan1
1MIT 2MIT Lincoln Laboratory
- This paper addresses a fundamental mismatch between reinforcement learning (RL) and optimal safe controller synthesis that results in poor performance on low-probability states within the safe set.
- We propose Feasibility-Guided Exploration (FGE), a method that simultaneously identifies safe initial conditions and solves the optimal control problem over these conditions using reinforcement learning.
- FGE achieves over 50% more coverage than existing state-of-the-art on challenging initial conditions across tasks in the MuJoCo simulator.
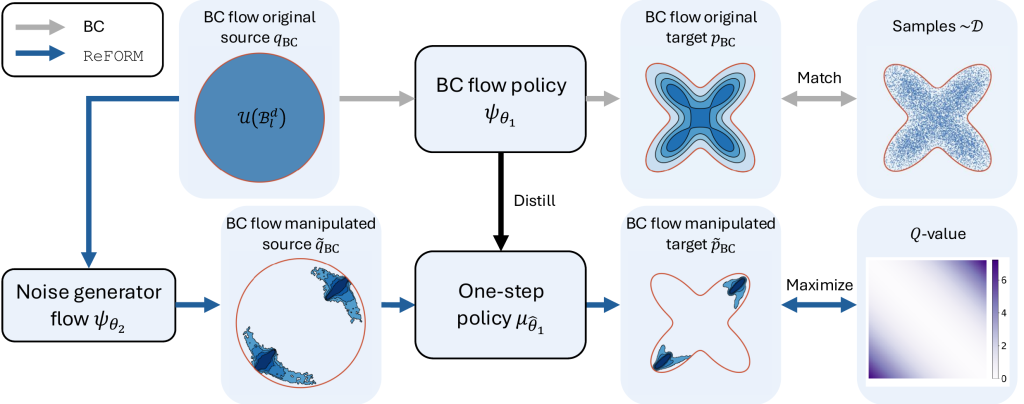
ReFORM: Reflected Flows for On-Support Offline RL via Noise Manipulation
Songyuan Zhang, Oswin So1, H M Sabbir Ahmad3, Eric Yu1, Matthew Cleaveland2, Mitchell Black2,
Chuchu Fan1
1MIT 2MIT Lincoln Laboratory 3Boston University
- ReFORM is an offline RL algorithm that utilizes a 2-stage flow-based policy to enforce the support constraint by construction, avoiding out-of-distribution errors without constraining policy improvement.
- We propose applying reflected flow to generate constrained multimodal noise for the BC flow policy, thereby mitigating OOD errors while maintaining the multimodal policy.
- Extensive experiments on 40 challenging tasks with datasets of different qualities demonstrate that, with a constant set of hyperparameters, ReFORM dominates all baselines using flow policy structures with the best hand-tuned hyperparameters on the performance profile curve.



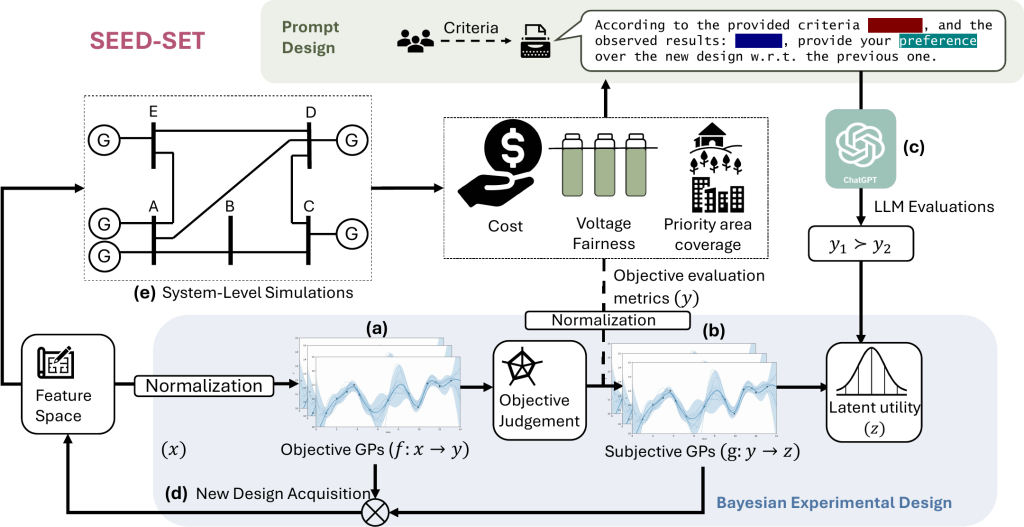
SEED-SET: Scalable Evolving Experimental Design for System-level Ethical Testing
Anjali Parashar1, Yingke Li1, Eric Yu1, Fei Chen1, James Neidhoefer1, Devesh Upadhyay2,
Chuchu Fan1
1MIT 2SAAB
- As autonomous systems are increasingly deployed in high-stakes human-centric domains such as drone emergency rescue, it becomes critical for us to evaluate their ethical alignment.
- We propose SEED-SET, a Bayesian experimental design framework that incorporates domain-specific objective evaluations and subjective value judgments from stakeholders.
- We validate our approach on two applications and find our method provides an interpretable and efficient trade-off between exploration and exploitation, generating up to 2x optimal test candidates compared to baselines, with 1.25x improvement in coverage of high dimensional search spaces.
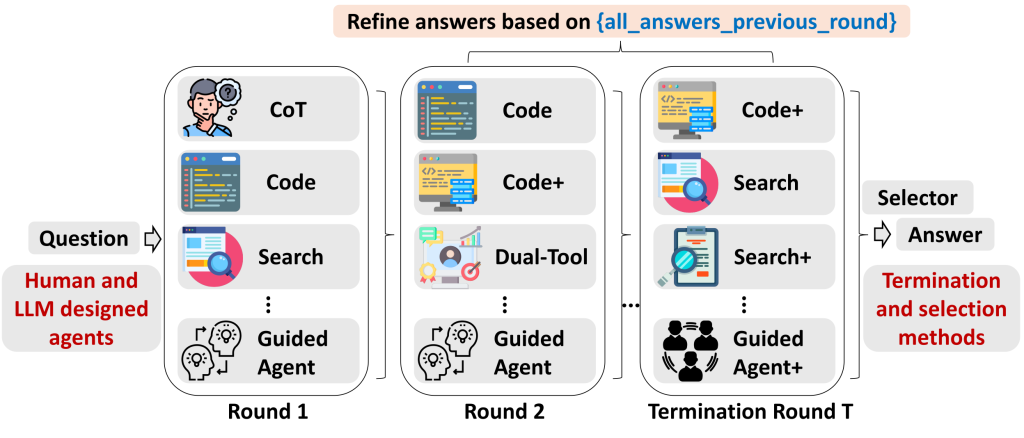
TUMIX: Multi-Agent Test-Time Scaling with Tool-Use Mixture
Yongchao Chen1,2, Jiefeng Chen3, Rui Meng3, Ji Yin1, Na Li 2, Chuchu Fan1, Chi Wang4,
Tomas Pfister3, Jinsung Yoon3
1MIT 2Harvard 3Google Cloud AI Research 4Google DeepMind
- Method: Proposes TUMIX (Tool-Use Mixture), a multi-agent test-time scaling framework that runs diverse tool-augmented agents (text, code, search) in parallel and iteratively refines answers via cross-agent sharing and majority voting.
- Key Insights: Agent diversity and quality matter more than scale alone; combining Code Interpreter and Search increases coverage and accuracy. An LLM-based termination strategy stops refinement adaptively, preserving performance at ~49% inference cost.
- Results: TUMIX outperforms strong test-time scaling baselines on HLE, GPQA, and AIME, achieving up to +3.55% average improvement over the best baseline at similar cost, with further gains under additional scaling.
R1-Code-Interpreter: LLMs Reason with Code via Supervised and Multi-Stage Reinforcement Learning
Yongchao Chen1,2, Yueying Liu3, Junwei Zhou4, Yilun Hao1, Jingquan Wang5, Yang Zhang6, Na Li 2,
Chuchu Fan1
1MIT 2Harvard 3University of Illinois Urbana-Champaign 4University of Michigan 5University of Wisconsin–Madison 6MIT-IBM Watson AI Lab
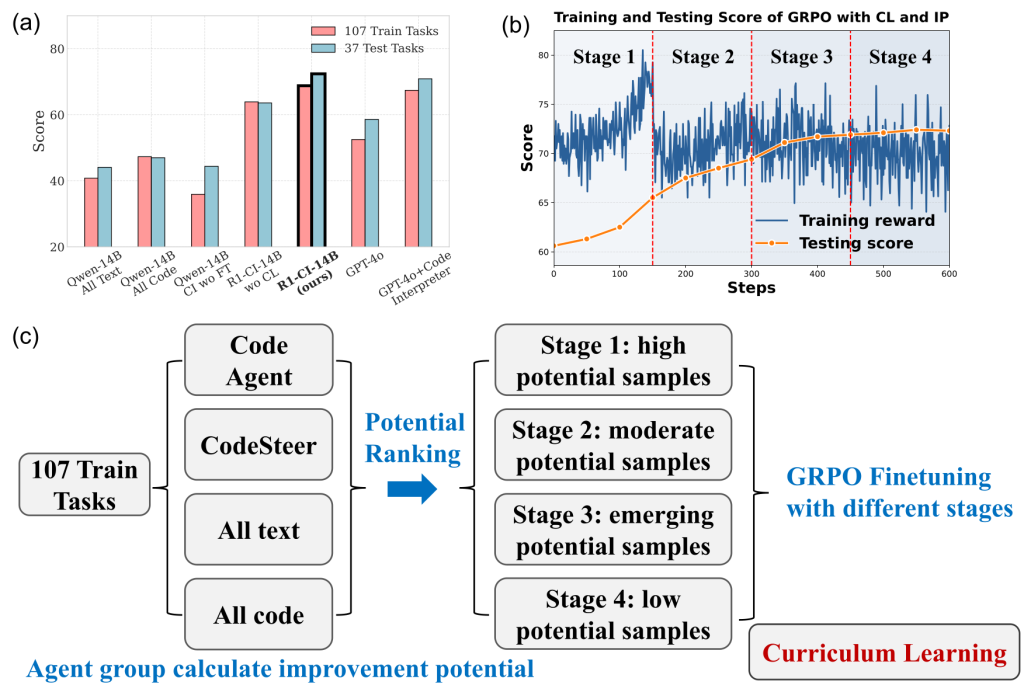
- Problem & Approach: Vanilla RL struggles to train LLMs to use a Code Interpreter across diverse tasks due to task heterogeneity and sparse rewards. The paper proposes R1-Code-Interpreter (R1-CI), combining supervised fine-tuning with multi-stage GRPO reinforcement learning guided by improvement potential to effectively integrate multi-turn text–code reasoning.
- Key Innovation: Introduces a potential-based curriculum learning strategy that prioritizes samples with highest learning signal (success rate near 50%), substantially improving RL gains over standard GRPO.
- Results: The best model, R1-CI-14B, achieves 72.4% test accuracy, outperforming GPT-4o (58.6%) and GPT-4o with Code Interpreter (70.9%), while showing emergent self-checking behavior and improved generalization.
Discrete Adjoint Matching
Oswin So1, Brian Karrer2, Chuchu Fan1, Ricky T. Q. Chen2, Guan-Horng Liu2
1MIT 2FAIR at Meta
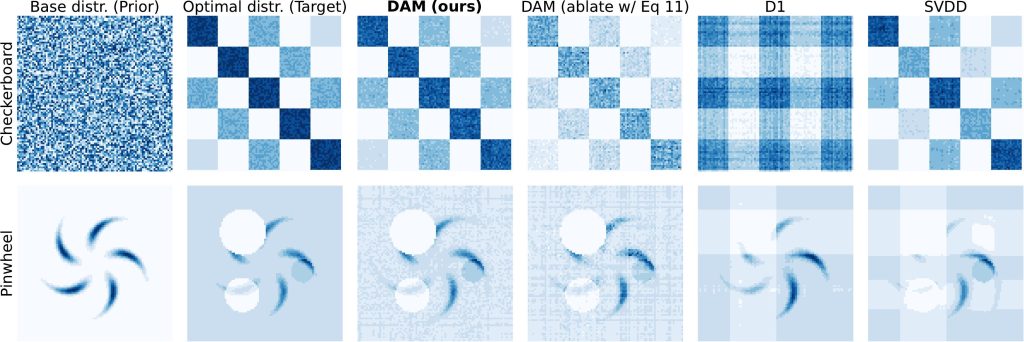
- Bridging a Critical Gap in Discrete Generative Modeling: Diffusion-based LLMs are a promising alternative to autoregressive models, but no principled fine-tuning methods existed for their discrete state spaces — where gradients don’t exist and continuous methods break down. DAM introduces the discrete adjoint, which recovers gradient-like information in discrete domains, enabling the same elegant regression-based fine-tuning that made Adjoint Matching so successful in continuous settings.
- A Theoretically Grounded Framework for Reward Optimization: DAM solves entropy-regularized reward optimization for Continuous-Time Markov Chains, providing the first discrete variant of Adjoint Matching with a well-defined fixed-point guarantee — the unique fixed point of the matching objective is the optimal transition rate.
- State-of-the-Art Results on Mathematical Reasoning: Applied to LLaDA-8B-Instruct, DAM achieves 87.1% accuracy on Sudoku, dramatically outperforming both the base LLaDA-8B model and the D1 fine-tuning method, demonstrating that diffusion-based LLMs can be effectively steered toward complex reasoning tasks through principled reward optimization.
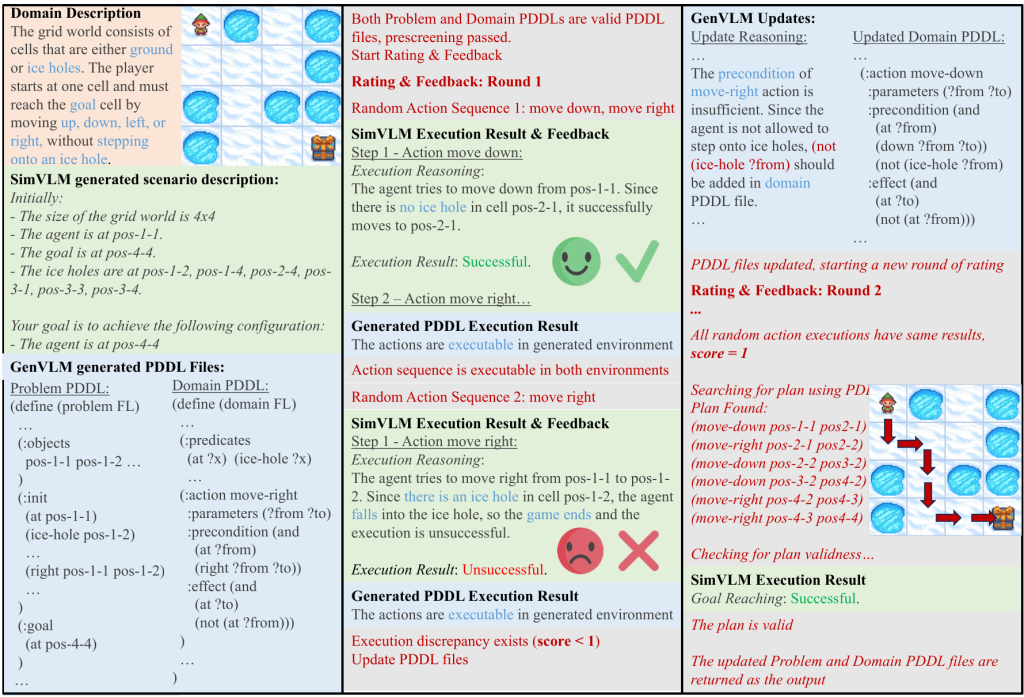
Simulation to Rules: A Dual-VLM Framework for Formal Visual Planning
Yilun Hao1,Yongchao Chen1,2, Chuchu Fan1, Yang Zhang3
1MIT 2Harvard 3MIT-IBM Watson AI Lab
- Current VLMs lack precise spatial understanding and long-horizon reasoning, while formal PDDL planners depend on structured domain and problem files and cannot directly interpret visual inputs. This paper addresses the challenge of visual long-horizon planning by combining the strength of VLMs and PDDL.
- We propose VLMFP, a Dual-VLM-guided framework that autonomously generates PDDL domain and problem files for visual planning, which, to our knowledge, is the first framework to leverage visual inputs to generate both PDDL files without human feedback or direct environment access.
- VLMFP notably achieves 70.0% and 54.1% success rates with a fine-tuned Qwen2-VL-7B model as the SimVLM and GPT-4o as the GenVLM, outperforming the best baseline by 39.3% and 21.8% for unseen instances in seen and unseen appearances, respectively. Furthermore, VLMFP achieves multiple levels of generalizability to unseen instances, appearances, and game rules.